--
分类的指标分析
分类是我们经常用的一种预测模型,比如我们用机器学习或者其他的什么方法来判断一封邮件是否是垃圾邮件,一张照片上是否包含有一只猫,等等。
如何判断分类结果的好坏? 这些判断的指标有:
1. accuracy,正确率, 就是在所有的样本中,你做了正确分类所占的比例。
2. precision,也就是准确率,就是你判断该标签为 “是” 的的那些样本中,真正属于 “是” 的比例。
3. recall,就是那些所有应该被标注为为 “是” 的样本,有多少被你挑出来打上 “是” 的标签。
4. f1 score,也就是 precision 和 recall 的调和平均数,即:
f1_score = 2 * (precision * recall ) / (precision + recall)
用一个confusion matrix 混淆矩阵,我们可以很容易计算出这些数值。
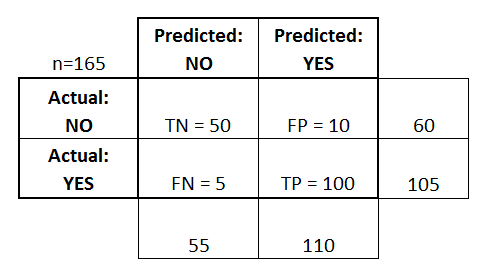
TP 是 True-Positive 的简称,表示对于该标签,实际为正,判断为正
TN 是 True-Negative 的简称,表示对于该标签,实际为负,判断为负
FP 是 False-Positive 的简称,表示对于该标签,实际为负,判断为正
FN 是 False-Negative 的简称,表示对于该标签,实际为正,判断为负
对于上图,我们可以很容易计算出:
accuracy = ( TP + TN ) / (TP + TN + FP + FN) = ( 100 + 50 ) / 165 = 0.91
precision = TP / (TP + FP) = 100 / (100 + 10) = 0.95
recall = TP / (TP + FN) = 100 / (100 + 5) = 0.90
f1 = 2 * precision * recall / (precision + recall) = 0.93
这里每个量衡量的指标有所不同,如果你很看重 precision,那么表示你倾向于 “宁可放过一千,也不错杀一个”。
如果你很看重 recall,那么表示你倾向于 “宁可错杀一千,也不放过一个”。
一般来说,f1 是一个比较好的综合考量指标。
而如果你有好几个分类,该如何计算 precision 和recall ? sklearn 提供了一系列的函数帮我们计算,
sklearn.metrics.precision_score(y_true, y_pred, labels, pos_label, average) sklearn.metrics.recall_score(y_true, y_pred, labels, pos_label, average) sklearn.metrics.f1_score(y_true, y_pred, labels, pos_label, average)
一般而言,我们有两种方法来计算,
1. 针对每一种 label,我们计算出一个metrics,然后求平均值
2. 针对所有的 label,计算出metrics
什么叫做针对所有label? 其实在这种情况下,metrics 只有一个数值,accuracy 和precision 和recall 一模一样,都是 所有分类正确的样本数 / 总样本数
这两种情况,就是对应于 average = 'macro' 和 'micro'
我们一般可以选择 macro。