--
迁移学习 2
VGGNet
利用 VGG 来进行迁移学习。
VGGNet 是 2014 年的 ImageNet 比赛的冠军,相比于 AlexNet,在于它层数较多,而且每一层都利用了 3*3 的小卷积核。
相比于 Alex Net 的 7*7 大卷积核,用多个 (3个)3 *3 的 卷积层能够取得相同的效果,而且,
中间有了三层 ReLU 非线性层,能够做出更加细致的判别。
而且参数更加少了,在比方说输入输出层都是 C ,小卷积网络的参数数目是 3 * (3 * 3 * C *C),
而大卷积网络的参数数目是 7* 7 *C * C (考虑 bias 的参数的话,为 3* (3*3+1) *C *C 和 7 * (7*7 +1) *C * C)
训练往往是一个很难的事情,对于这样很深的网络以及巨量的参数下。
作者需要找比较好的初始值,一开始,我们训练 VGG11 模型,因为相对来说比较简单。
作者用 VGG11 的值作为初始值,来训练 VGG16.
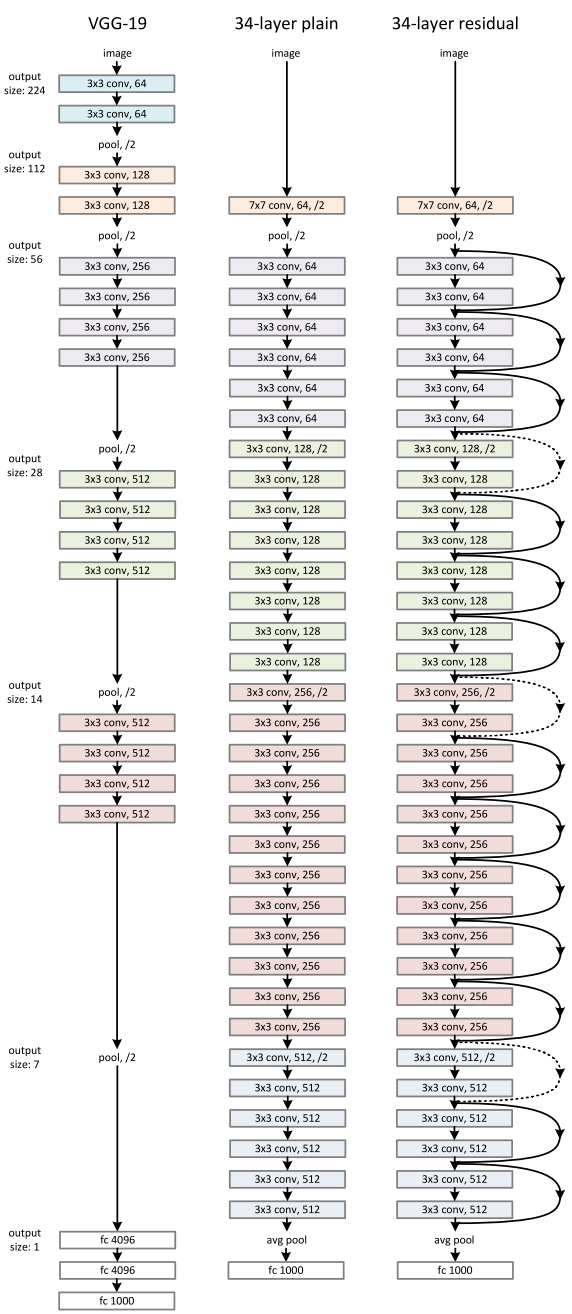
给几个图看一下 VGGNet 的结构:
各种深浅不一的 VGGNet 的结构:
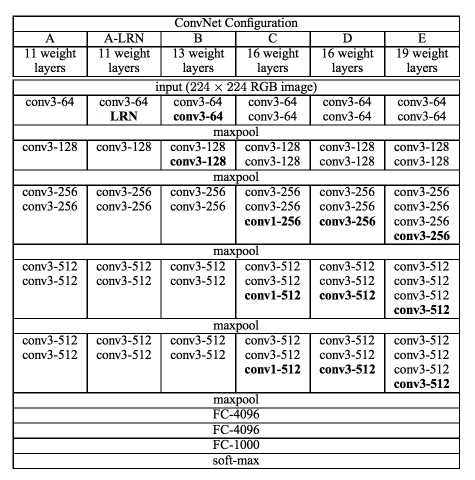
AlexNet 和 VGGNet (VGG13) 的直观比较:
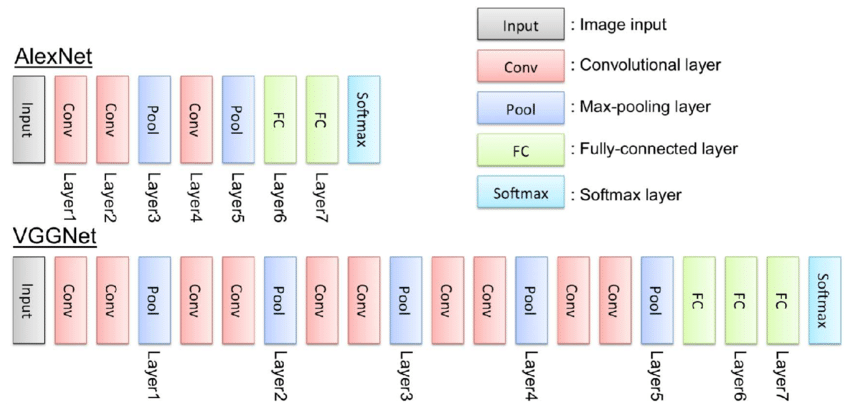
VGG16 的结构示意图
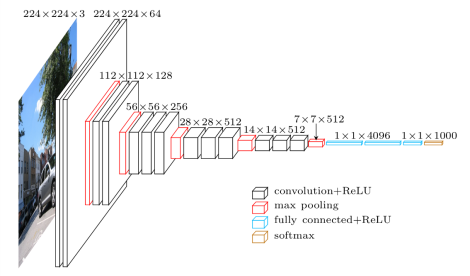
ResNet
paper显而易见,从 LeNet 到 AlexNet 再到 VGGNet 到 GoogLeNet,网络的层数在不断增加,效果也越来越好
但是同时有一个问题也越来越显著,就是梯度消失(Gradient Vanish)或者梯度爆炸(Gradient Exploding)。
而 ResNet 通过一个 short-cut 来跳过了一些层以进行从较为前面的 layer 到较为靠后 layer 的直接联通, 可以在一定程度上防止 梯度消失的问题。
ResNet 的结构
除了 shortcut,ResNet 还采用了 Bottleneck 的结构,也就是用 1*1 kernel 64 ==> 3*3 krnel 64 ==> 1*1 kernel 256 来代替 3*3 kernel 256
这样参数更加少,计算量也更加少了。
model 下载:
vgg 100
ResNet BottleNeck Features
Inception v3 bottleneck features 100 (GoogLeNet)
迁移学习
1. 首先下载源代码,这里已经帮你写好了很多了。 github2. 下载数据集
这里的代码我们都用 Keras 来实现,数据集我们用的是 CIFAR10
from keras.datasets import cifar10
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# y_train.shape is 2d, (50000, 1). While Keras is smart enough to handle this
# it's a good idea to flatten the array.
y_train = y_train.reshape(-1)
y_test = y_test.reshape(-1)
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.3, random_state=42, stratify = y_train)
print('X_train shape = ', X_train.shape)
print('X_test shape = ', X_test.shape)
print('y_train shape = ', y_train.shape)
print('y_test shape = ', y_test.shape)
当然,CIFAR10 是 10 分类,与ImageNet 和 German Traffic Sign 的分类数目都不相同,我们要做适当的改变。
定义一个辅助函数,用来从 pickle 文件中获取训练数据
def load_bottleneck_data(training_file, validation_file):
"""
Utility function to load bottleneck features.
Arguments:
training_file - String
validation_file - String
"""
print("Training file", training_file)
print("Validation file", validation_file)
with open(training_file, 'rb') as f:
train_data = pickle.load(f)
with open(validation_file, 'rb') as f:
validation_data = pickle.load(f)
X_train = train_data['features']
y_train = train_data['labels']
X_val = validation_data['features']
y_val = validation_data['labels']
return X_train, y_train, X_val, y_val
3. feature extraction
import pickle
import tensorflow as tf
import numpy as np
from keras.layers import Input, Flatten, Dense
from keras.models import Model
flags = tf.app.flags
FLAGS = flags.FLAGS
# command line flags
flags.DEFINE_string('training_file', '', "Bottleneck features training file (.p)")
flags.DEFINE_string('validation_file', '', "Bottleneck features validation file (.p)")
flags.DEFINE_integer('epochs', 50, "The number of epochs.")
flags.DEFINE_integer('batch_size', 256, "The batch size.")
def main(_):
# load bottleneck data
X_train, y_train, X_val, y_val = load_bottleneck_data(FLAGS.training_file, FLAGS.validation_file)
print(X_train.shape, y_train.shape)
print(X_val.shape, y_val.shape)
nb_classes = len(np.unique(y_train))
# define model
input_shape = X_train.shape[1:]
inp = Input(shape=input_shape)
x = Flatten()(inp)
x = Dense(nb_classes, activation='softmax')(x)
model = Model(inp, x)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# train model
model.fit(X_train, y_train, epochs=FLAGS.epochs, batch_size=FLAGS.batch_size, validation_data=(X_val, y_val), shuffle=True)
# parses flags and calls the `main` function above
if __name__ == '__main__':
tf.app.run()
这里我们通过 tf.app 来定义了 命令行参数,
我们可以通过下面方式来跑>>> python feature_extraction.py --training_file vgg_cifar10_100_bottleneck_features_train.p --validation_file vgg_cifar10_bottleneck_features_validation.p
我们可以导入不同的数据,也就是对于CIFAR10的数据集在VGG,Inception,以及 ResNet 上的 feature extraction 得到的新的数据,通过一个全连接网络来继续训练。
当然这里有一点就是训练集产生的 feature 已经帮你准备好了,如果你用自己的数据集,然后想用 feature extraction, 那么也要像 在 transfer_learning 1 那样,搭建一个自己的网络,然后开始固定权重,进行训练。